Take-home Exercise 3: Predicting HDB Public Housing Resale Pricies using Geographically Weighted Methods
1 Setting The Scene
Housing is an essential component of household wealth worldwide. Buying a housing has always been a major investment for most people. The price of housing is affected by many factors. Some of them are global in nature such as the general economy of a country or inflation rate. Others can be more specific to the properties themselves. These factors can be further divided to structural and locational factors. Structural factors are variables related to the property themselves such as the size, fitting, and tenure of the property. Locational factors are variables related to the neighbourhood of the properties such as proximity to childcare centre, public transport service and shopping centre.
Conventional, housing resale prices predictive models were built by using Ordinary Least Square (OLS) method. However, this method failed to take into consideration that spatial autocorrelation and spatial heterogeneity exist in geographic data sets such as housing transactions. With the existence of spatial autocorrelation, the OLS estimation of predictive housing resale pricing models could lead to biased, inconsistent, or inefficient results (Anselin 1998). In view of this limitation, Geographical Weighted Models were introduced for calibrating predictive model for housing resale prices.
2 The Task
In this take-home exercise, we are tasked to predict HDB resale prices at the sub-market level (i.e. HDB 3-room, HDB 4-room and HDB 5-room) for the month of January and February 2023 in Singapore. The predictive models must be built by using by using conventional OLS method and GWR methods. You are also required to compare the performance of the conventional OLS method versus the geographical weighted methods.
3 Installing Packages
sf: used for importing, managing and processing geospatial data
tidyverse: collection of R packages designed for data wrangling
tmap: used for creating thematic maps, such as chloropleth and bubble maps
httr: used to make API calls, such as GET requests
jsonlite: a JSON parser that can convert from JSON to the appropraite R data types
rvest: Wrappers around the ‘xml2’ and ‘httr’ packages to make it easy to download, then manipulate, HTML and XML.
sp: Classes and methods for spatial data
ggpubr: used for multivariate data visualisation & analysis
corrplot: used for multivariate data visualisation & analysis
broom: The broom package takes the messy output of built-in functions in R, such as lm, nls, or t.test, and turns them into tidy tibbles.
olsrr: used for building least squares regression models
spdep: used to create spatial weights matrix objects, global and local spatial autocorrelation statistics and related calculations (e.g. spatially lag attributes)
GWmodel: provides a collection of localised spatial statistical methods, such as summary statistics, principal components analysis, discriminant analysis and various forms of GW regression
devtools: used for installing any R packages which is not available in RCRAN
lwgeom: Functions for SF
maptools: Tools for handling spatial objects
matrixstats: a set of high-performing functions for operating on rows and columns of matrices
units: Measurement Units for R Vectors
metrics: Evaluation metrics for machine learning
gtsummary: provides an elegant and flexible way to create publication-ready analytical and summary tables using the R programming language
rsample: The rsample package provides functions to create different types of resamples and corresponding classes for their analysis
spatialml: allows for a geographically weighted random forest regression to include a function to find the optimal bandwidth
Linking to GEOS 3.9.3, GDAL 3.5.2, PROJ 8.2.1; sf_use_s2() is TRUE
Loading required package: tidyverse
── Attaching packages ─────────────────────────────────────── tidyverse 1.3.2 ──
✔ ggplot2 3.4.1 ✔ purrr 1.0.1
✔ tibble 3.1.8 ✔ dplyr 1.0.10
✔ tidyr 1.3.0 ✔ stringr 1.5.0
✔ readr 2.1.3 ✔ forcats 0.5.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
Loading required package: tmap
Loading required package: httr
Loading required package: jsonlite
Attaching package: 'jsonlite'
The following object is masked from 'package:purrr':
flatten
Loading required package: rvest
Attaching package: 'rvest'
The following object is masked from 'package:readr':
guess_encoding
Loading required package: sp
Loading required package: ggpubr
Loading required package: corrplot
corrplot 0.92 loaded
Loading required package: broom
Loading required package: olsrr
Attaching package: 'olsrr'
The following object is masked from 'package:datasets':
rivers
Loading required package: spdep
Loading required package: spData
To access larger datasets in this package, install the spDataLarge
package with: `install.packages('spDataLarge',
repos='https://nowosad.github.io/drat/', type='source')`
Loading required package: GWmodel
Loading required package: maptools
Checking rgeos availability: TRUE
Please note that 'maptools' will be retired during 2023,
plan transition at your earliest convenience;
some functionality will be moved to 'sp'.
Loading required package: robustbase
Loading required package: Rcpp
Loading required package: spatialreg
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Attaching package: 'spatialreg'
The following objects are masked from 'package:spdep':
get.ClusterOption, get.coresOption, get.mcOption,
get.VerboseOption, get.ZeroPolicyOption, set.ClusterOption,
set.coresOption, set.mcOption, set.VerboseOption,
set.ZeroPolicyOption
Welcome to GWmodel version 2.2-9.
Loading required package: devtools
Loading required package: usethis
Loading required package: lwgeom
Linking to liblwgeom 3.0.0beta1 r16016, GEOS 3.9.1, PROJ 7.2.1
Warning in fun(libname, pkgname): GEOS versions differ: lwgeom has 3.9.1 sf has
3.9.3
Warning in fun(libname, pkgname): PROJ versions differ: lwgeom has 7.2.1 sf has
8.2.1
Loading required package: matrixStats
Attaching package: 'matrixStats'
The following objects are masked from 'package:robustbase':
colMedians, rowMedians
The following object is masked from 'package:dplyr':
count
Loading required package: units
udunits database from C:/R-4.2.2/library/units/share/udunits/udunits2.xml
Loading required package: Metrics
Loading required package: gtsummary
Loading required package: rsample
Attaching package: 'rsample'
The following object is masked from 'package:Rcpp':
populate
Loading required package: SpatialML
Loading required package: ranger
Loading required package: caret
Loading required package: lattice
Attaching package: 'caret'
The following objects are masked from 'package:Metrics':
precision, recall
The following object is masked from 'package:httr':
progress
The following object is masked from 'package:purrr':
lift
4 The Data
The following datasets are derived from the respective sources.
library(knitr)library(kableExtra)
Warning: package 'kableExtra' was built under R version 4.2.3
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rows
Rows: 148479 Columns: 11
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): month, town, flat_type, block, street_name, storey_range, flat_mode...
dbl (3): floor_area_sqm, lease_commence_date, resale_price
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Let’s see what aspatial data we are working with
head(hdb_resale)
# A tibble: 6 × 11
month town flat_…¹ block stree…² store…³ floor…⁴ flat_…⁵ lease…⁶ remai…⁷
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr>
1 2017-01 ANG MO … 2 ROOM 406 ANG MO… 10 TO … 44 Improv… 1979 61 yea…
2 2017-01 ANG MO … 3 ROOM 108 ANG MO… 01 TO … 67 New Ge… 1978 60 yea…
3 2017-01 ANG MO … 3 ROOM 602 ANG MO… 01 TO … 67 New Ge… 1980 62 yea…
4 2017-01 ANG MO … 3 ROOM 465 ANG MO… 04 TO … 68 New Ge… 1980 62 yea…
5 2017-01 ANG MO … 3 ROOM 601 ANG MO… 01 TO … 67 New Ge… 1980 62 yea…
6 2017-01 ANG MO … 3 ROOM 150 ANG MO… 01 TO … 68 New Ge… 1981 63 yea…
# … with 1 more variable: resale_price <dbl>, and abbreviated variable names
# ¹flat_type, ²street_name, ³storey_range, ⁴floor_area_sqm, ⁵flat_model,
# ⁶lease_commence_date, ⁷remaining_lease
4.1.1 Filtering HDB Resale Aspatial Data
From the results above in section 3.1, we can see that the data starts from Year 2017. But for this assignment we are only focusing on 1st January 2021 to 31st December 2022. Thus the below code chunk will do the filtering.
Now let us see what data we are working with and see if the data is what we have filtered.
head(hdb_filtered_resale)
# A tibble: 6 × 11
month town flat_…¹ block stree…² store…³ floor…⁴ flat_…⁵ lease…⁶ remai…⁷
<chr> <chr> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr>
1 2021-01 ANG MO … 4 ROOM 547 ANG MO… 04 TO … 92 New Ge… 1981 59 yea…
2 2021-01 ANG MO … 4 ROOM 414 ANG MO… 01 TO … 92 New Ge… 1979 57 yea…
3 2021-01 ANG MO … 4 ROOM 509 ANG MO… 01 TO … 91 New Ge… 1980 58 yea…
4 2021-01 ANG MO … 4 ROOM 467 ANG MO… 07 TO … 92 New Ge… 1979 57 yea…
5 2021-01 ANG MO … 4 ROOM 571 ANG MO… 07 TO … 92 New Ge… 1979 57 yea…
6 2021-01 ANG MO … 4 ROOM 134 ANG MO… 07 TO … 98 New Ge… 1978 56 yea…
# … with 1 more variable: resale_price <dbl>, and abbreviated variable names
# ¹flat_type, ²street_name, ³storey_range, ⁴floor_area_sqm, ⁵flat_model,
# ⁶lease_commence_date, ⁷remaining_lease
From the above output, it looks like it is according to the specifications that we wanted now.
The below code chunks will check if the months, room type are what we want to work with.
4.1.2 Checking for 4 Room Type Period
unique(hdb_filtered_resale$flat_type)
[1] "4 ROOM"
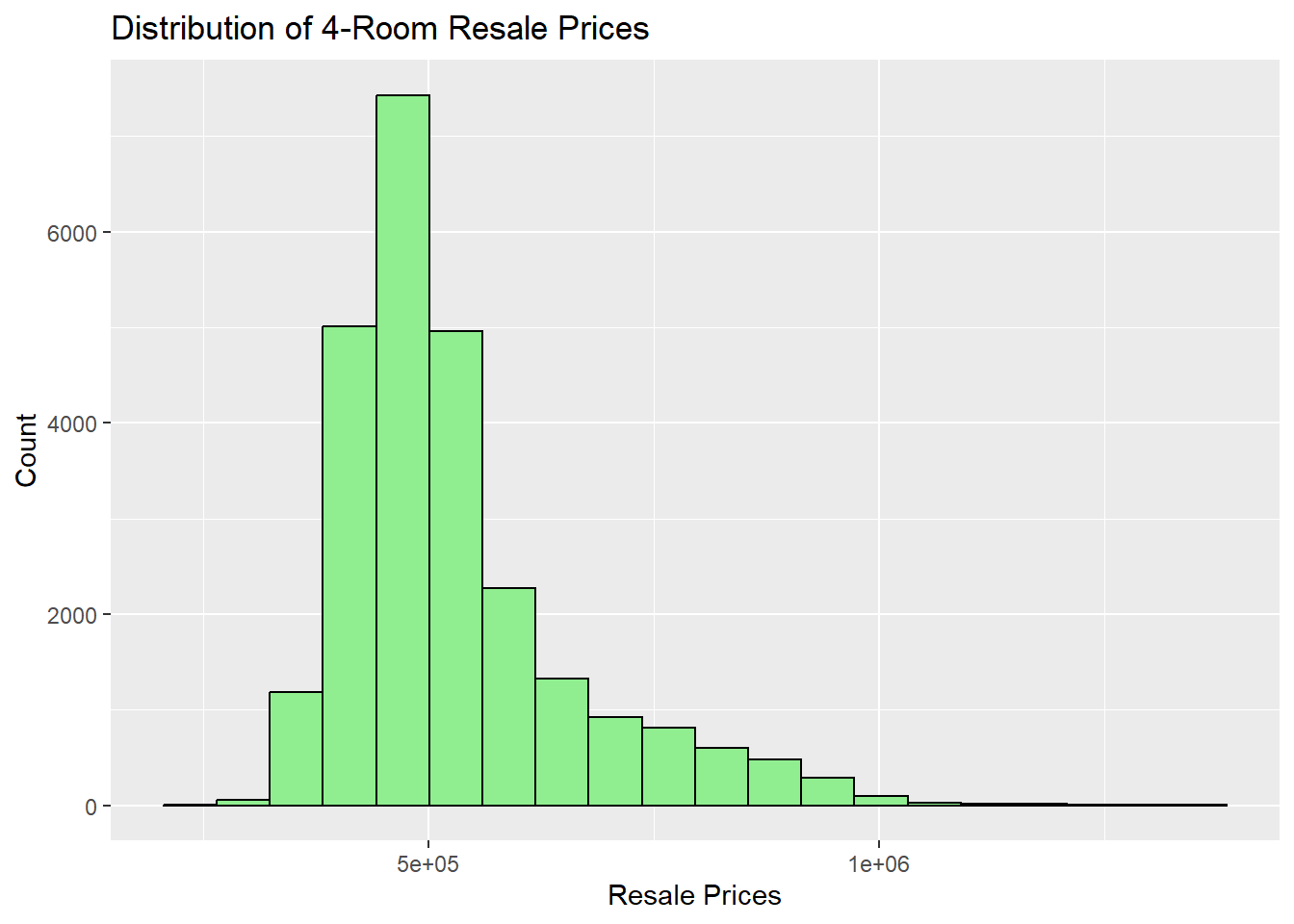
From the above output, the “hdb_resale_filtered” only consists of 4 Room which reflects our filter code in 3.1.1.
4.3.1.5 Creating a function to get the lat and long from OneMapSG
get_coords <-function(add_list){# Create a data frame to store all retrieved coordinates postal_coords <-data.frame()for (i in add_list){#print(i) r <-GET('https://developers.onemap.sg/commonapi/search?',query=list(searchVal=i,returnGeom='Y',getAddrDetails='Y')) data <-fromJSON(rawToChar(r$content)) found <- data$found res <- data$results# Create a new data frame for each address new_row <-data.frame()# If single result, append if (found ==1){ postal <- res$POSTAL lat <- res$LATITUDE lng <- res$LONGITUDE new_row <-data.frame(address= i, postal = postal, latitude = lat, longitude = lng) }# If multiple results, drop NIL and append top 1elseif (found >1){# Remove those with NIL as postal res_sub <- res[res$POSTAL !="NIL", ]# Set as NA first if no Postalif (nrow(res_sub) ==0) { new_row <-data.frame(address= i, postal =NA, latitude =NA, longitude =NA) }else{ top1 <-head(res_sub, n =1) postal <- top1$POSTAL lat <- top1$LATITUDE lng <- top1$LONGITUDE new_row <-data.frame(address= i, postal = postal, latitude = lat, longitude = lng) } }else { new_row <-data.frame(address= i, postal =NA, latitude =NA, longitude =NA) }# Add the row postal_coords <-rbind(postal_coords, new_row) }return(postal_coords)}
Getting Lat and Long of the addresses retrieved in 3.3.1.4
#putting eval false because the data is already created in the RDS file in 3.3.1.8, and it takes quite some time to load the function. To save time in rendering, i will put a false to evaluation for this section.latandlong <-get_coords(address)
4.3.1.6 Checking for NA Values
Checking if there is any NA values in Lat and Long
latandlong[(is.na(latandlong))]
Thankfully no NA values from the API!
4.3.1.7 Combining Fields
Combining the lat and long retrieved for each address to the tbl.df created in 3.3.1.1
hdb_resale_latlong <-left_join(hdb_resale_transformed, latandlong, by =c('address'='address'))
4.3.1.8 Creating RDS File for Aspatial Data
As mentioned by Prof Kam during lesson, reading RDS files will be more efficient thus the following code.
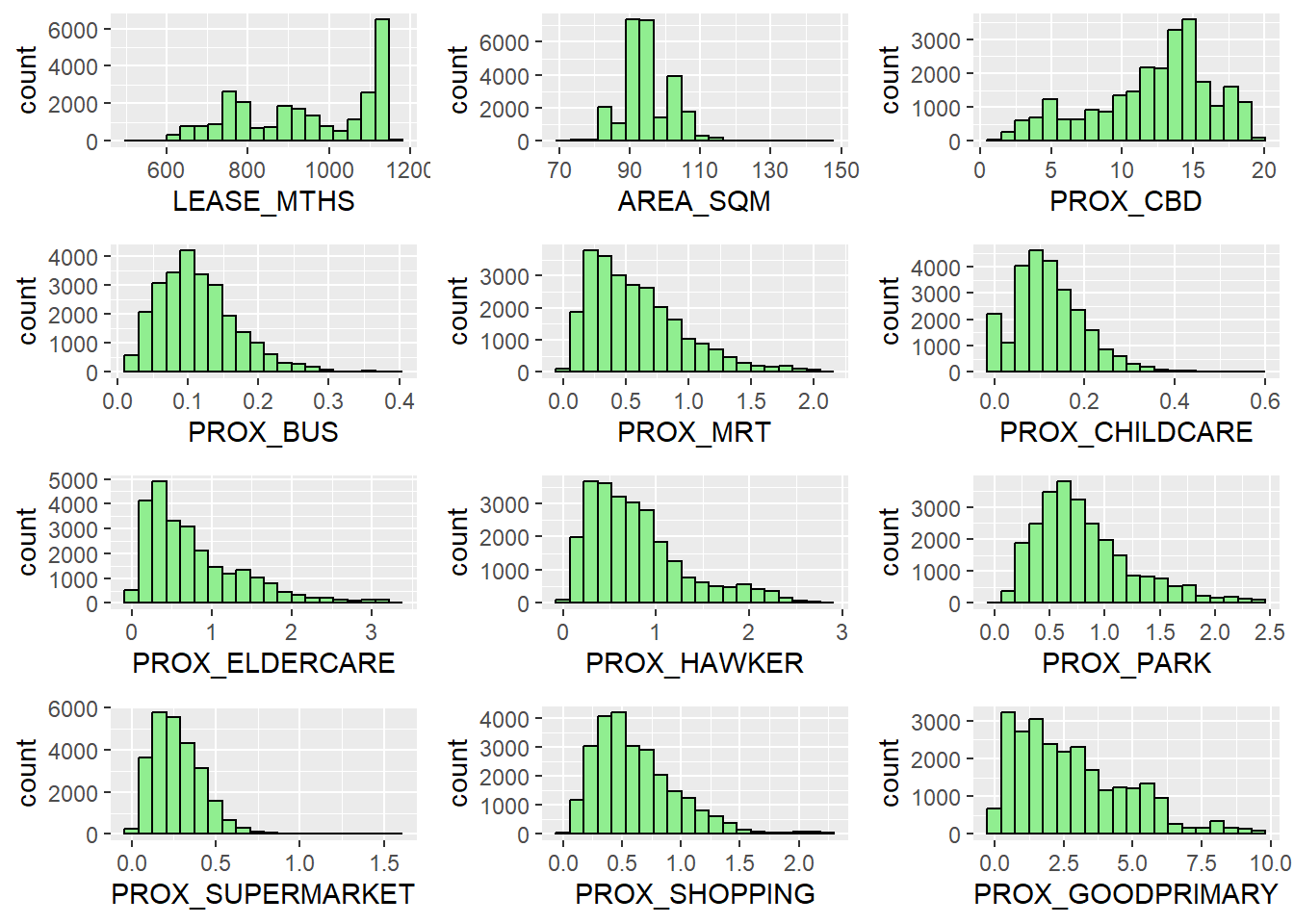
List of locational factors can be found here. Computing locational factors so it can be used to build the pricing model which will be used in the later section.
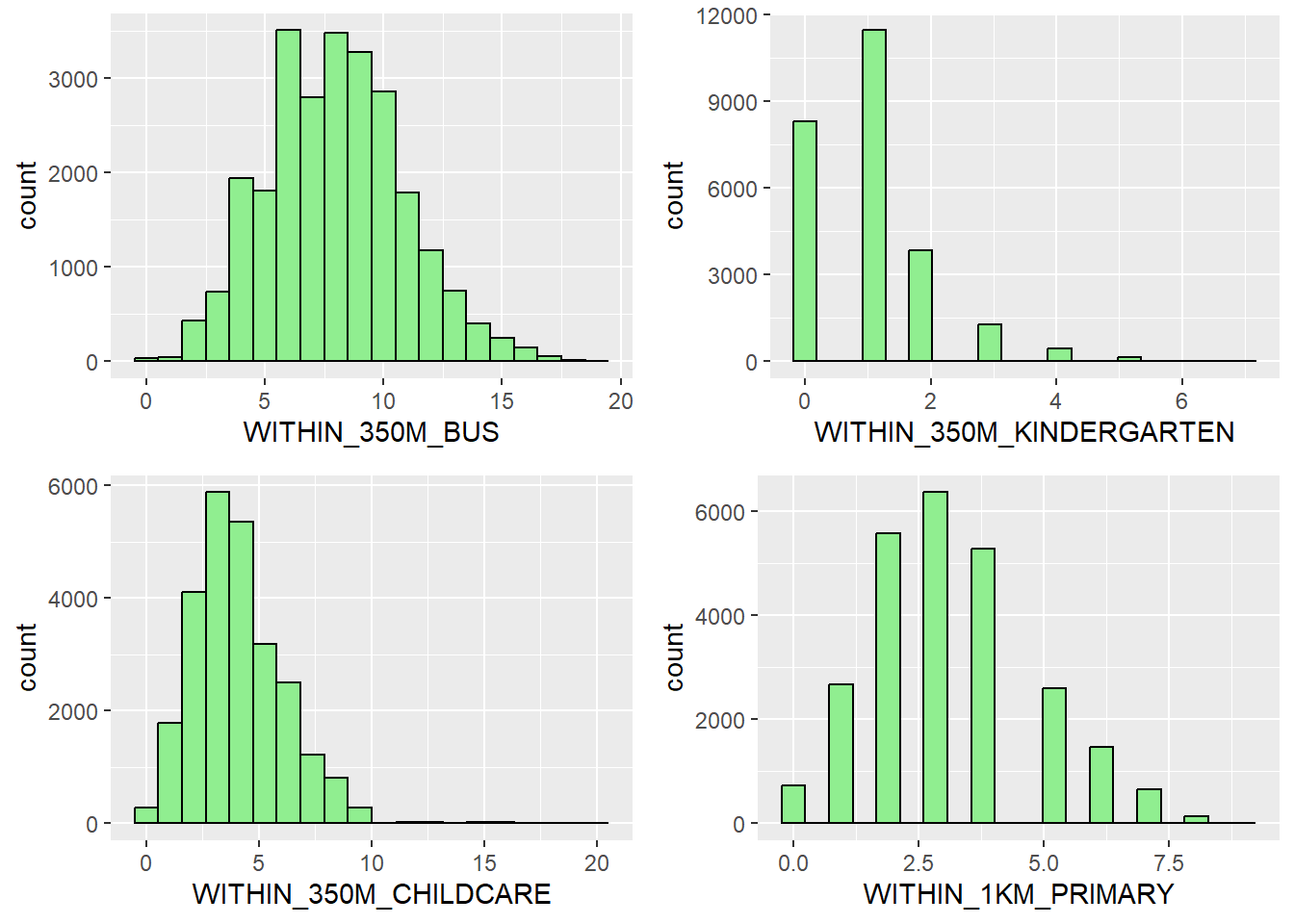
List of locational factors with radius can be found here. Computing locational factors with radius so it can be used to build the pricing model which will be used in the later section.
Saving the hdb_resale_main_sf which consists of the proximity computation into rds format for efficient processing in the subsequent section. But before exporting it into rds format, let us rename the columns so that it is easier to interpret.